一、查询条件包含or,索引失效
新建一个user表,它有一个普通索引userId,结构如下:
CREATE TABLE `user` (
`id` int(11) NOT NULL AUTO_INCREMENT,
`userId` int(11) NOT NULL,
`age` int(11) NOT NULL,
`name` varchar(255) NOT NULL,
PRIMARY KEY (`id`),
KEY `idx_userId` (`userId`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8;转载参考:https://juejin.cn/post/6844904015872917517
执行一条查询sql,它是会走索引的,如下图所示:

把or条件+没有索引的age加上,并不会走索引,如图:
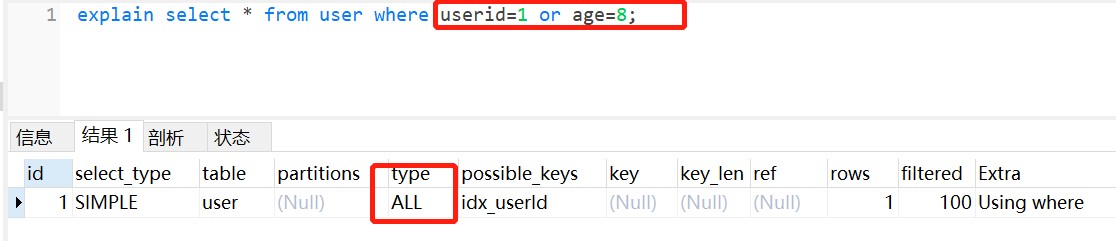
explain结果字段介绍说明:
id : 优先级,id值越大越优先;id值相同,从上往下 顺序执行
select_type :查询类型
table :表
type :索引类型
possible_keys :预测用到的索引
key :实际使用的索引
key_len :实际使用索引的长度
ref :表之间的引用,指明当前表所 参照的 字段
rows :通过索引查询到的数据量
Extra : 额外的信息
分析&结论
- 对于or+没有索引的age这种情况,假设它走了userId的索引,但是走到age查询条件时,它还得全表扫描,也就是需要三步过程: 全表扫描+索引扫描+合并
- 如果它一开始就走全表扫描,直接一遍扫描就完事。
- mysql是有优化器的,处于效率与成本,遇到or条件,索引可能失效,看起来也合情合理。
- 用or导致or左侧的userid索引失效
注意: 如果or条件的列都加了索引,索引可能会走的。
二、如果字段类型是字符串,where时一定用引号括起来
假设demo表结构如下:
CREATE TABLE `user` (
`id` int(11) NOT NULL AUTO_INCREMENT,
`userId` varchar(32) NOT NULL,
`name` varchar(255) NOT NULL,
PRIMARY KEY (`id`),
KEY `idx_userId` (`userId`) USING BTREE
) ENGINE=InnoDB AUTO_INCREMENT=2 DEFAULT CHARSET=utf8;userId为字符串类型,是B+树的普通索引,如果查询条件传了一个数字过去,它是不走索引的,如图所示: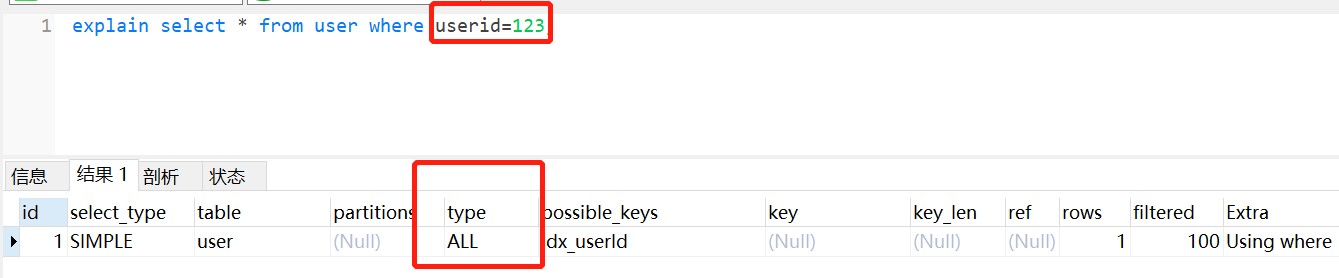
如果给数字加上’ ‘,也就是传一个字符串呢,当然是走索引,如下图: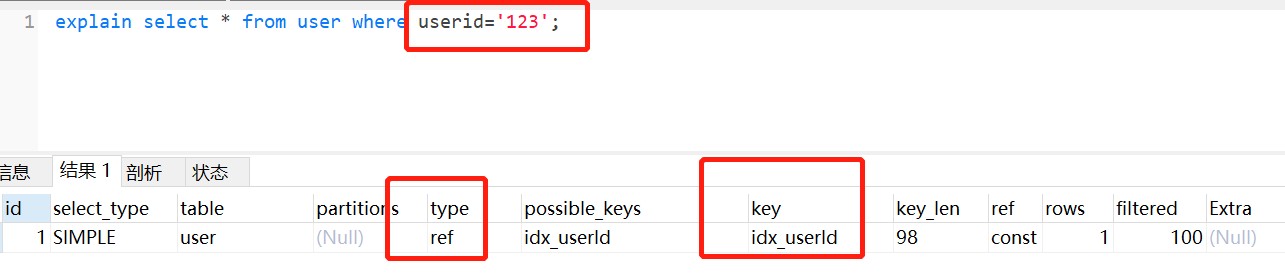
分析与结论
为什么第一条语句未加单引号就不走索引了呢? 这是因为不加单引号时,是字符串跟数字的比较,它们类型不匹配,MySQL会做隐式的类型转换,把它们转换为浮点数再做比较。
三、like通配符可能导致索引失效
并不是用了like通配符,索引一定失效,而是like查询是以%开头,才会导致索引失效。
表结构:
CREATE TABLE `user` (
`id` int(11) NOT NULL AUTO_INCREMENT,
`userId` varchar(32) NOT NULL,
`name` varchar(255) NOT NULL,
PRIMARY KEY (`id`),
KEY `idx_userId` (`userId`) USING BTREE
) ENGINE=InnoDB AUTO_INCREMENT=2 DEFAULT CHARSET=utf8;like查询以%开头,索引失效,如图: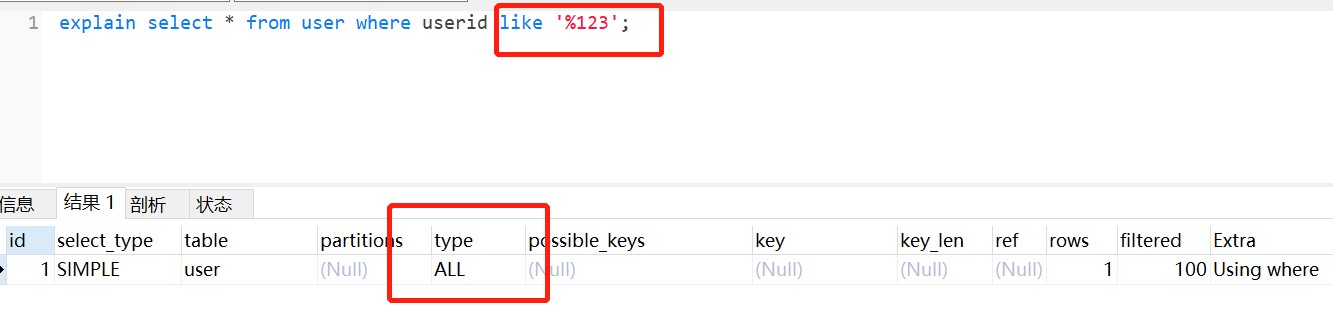
把%放后面,发现索引还是正常走的,如下:
把%加回来,改为只查索引的字段(覆盖索引),发现还是走索引,惊不惊喜,意不意外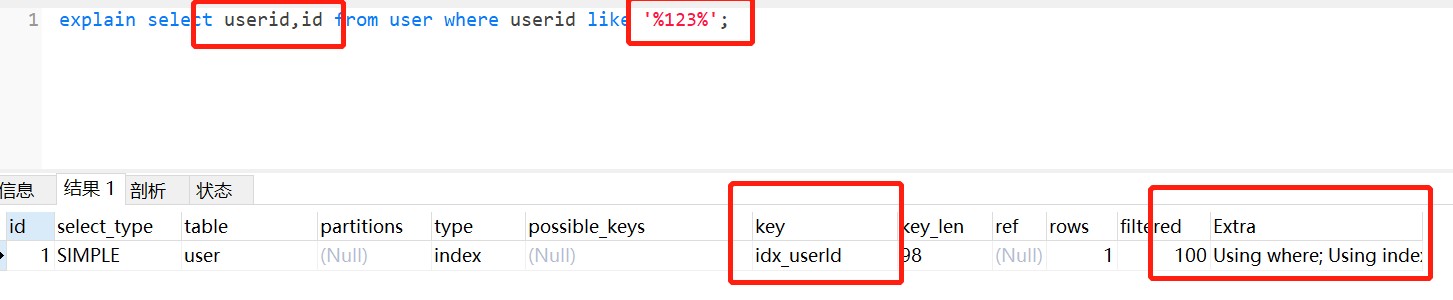
结论
like查询以%开头,会导致索引失效。可以有两种方式优化:
- 使用覆盖索引,覆盖索引包含所有满足查询需要的数据的索引
- 把 % 放后面
四、联合索引不要跨列或无序使用
表结构:(有一个联合索引idx_userid_age,userId在前,age在后)
CREATE TABLE `user` (
`id` int(11) NOT NULL AUTO_INCREMENT,
`userId` int(11) NOT NULL,
`age` int(11) DEFAULT NULL,
`name` varchar(255) NOT NULL,
PRIMARY KEY (`id`),
KEY `idx_userid_age` (`userId`,`age`) USING BTREE
) ENGINE=InnoDB AUTO_INCREMENT=2 DEFAULT CHARSET=utf8;在联合索引中,查询条件满足最左匹配原则时,索引是正常生效的。请看demo:

如果条件列不是联合索引中的第一个列,索引失效,如下:
复合索引,尽量使用全索引匹配
五、在索引列上使用mysql的内置函数,索引失效
表结构:
CREATE TABLE `user` (
`id` int(11) NOT NULL AUTO_INCREMENT,
`userId` varchar(32) NOT NULL,
`loginTime` datetime NOT NULL,
PRIMARY KEY (`id`),
KEY `idx_userId` (`userId`) USING BTREE,
KEY `idx_login_time` (`loginTime`) USING BTREE
) ENGINE=InnoDB AUTO_INCREMENT=2 DEFAULT CHARSET=utf8;虽然loginTime加了索引,但是因为使用了mysql的内置函数Date_ADD(),索引直接GG,如图:
六、对索引列运算(如,+、-、*、/ ),索引失效
表结构:
CREATE TABLE `user` (
`id` int(11) NOT NULL AUTO_INCREMENT,
`userId` varchar(32) NOT NULL,
`age` int(11) DEFAULT NULL,
PRIMARY KEY (`id`),
KEY `idx_age` (`age`) USING BTREE
) ENGINE=InnoDB AUTO_INCREMENT=2 DEFAULT CHARSET=utf8;虽然age加了索引,但是因为它进行运算,索引直接迷路了。。。 如图:
七、索引字段上使用(!= 或者 < >,not in)时,可能会导致索引失效
表结构:
CREATE TABLE `user` (
`id` int(11) NOT NULL AUTO_INCREMENT,
`userId` int(11) NOT NULL,
`age` int(11) DEFAULT NULL,
`name` varchar(255) NOT NULL,
PRIMARY KEY (`id`),
KEY `idx_age` (`age`) USING BTREE
) ENGINE=InnoDB AUTO_INCREMENT=2 DEFAULT CHARSET=utf8;虽然age加了索引,但是使用了!= 或者 < >,not in这些时,索引如同虚设。如下:

!= 和 < >两者都是不等于的意思,查阅网上资料说是!=是以前sql标准,<>是现在使用的sql标准,推荐使用<>。
复合索引不能使用不等于(!= <>)或is null (is not null),否则自身以及右侧所有全部失效。复合索引中如果有>,则自身和右侧索引全部失效。
八、索引字段上使用is null,is not null,可能导致索引失效
表结构:
CREATE TABLE `user` (
`id` int(11) NOT NULL AUTO_INCREMENT,
`card` varchar(255) DEFAULT NULL,
`name` varchar(255) DEFAULT NULL,
PRIMARY KEY (`id`),
KEY `idx_name` (`name`) USING BTREE,
KEY `idx_card` (`card`) USING BTREE
) ENGINE=InnoDB AUTO_INCREMENT=2 DEFAULT CHARSET=utf8;单个name字段加上索引,并查询name为非空的语句,其实会走索引的,如下:
单个card字段加上索引,并查询name为非空的语句,其实会走索引的,如下:
但是它两用or连接起来,索引就失效了,如下:
九、左连接查询或者右连接查询查询关联的字段编码格式不一样
可能导致索引失效。
新建两个表,一个user,一个user_job:
CREATE TABLE `user` (
`id` int(11) NOT NULL AUTO_INCREMENT,
`name` varchar(255) CHARACTER SET utf8mb4 DEFAULT NULL,
`age` int(11) NOT NULL,
PRIMARY KEY (`id`),
KEY `idx_name` (`name`) USING BTREE
) ENGINE=InnoDB AUTO_INCREMENT=2 DEFAULT CHARSET=utf8;
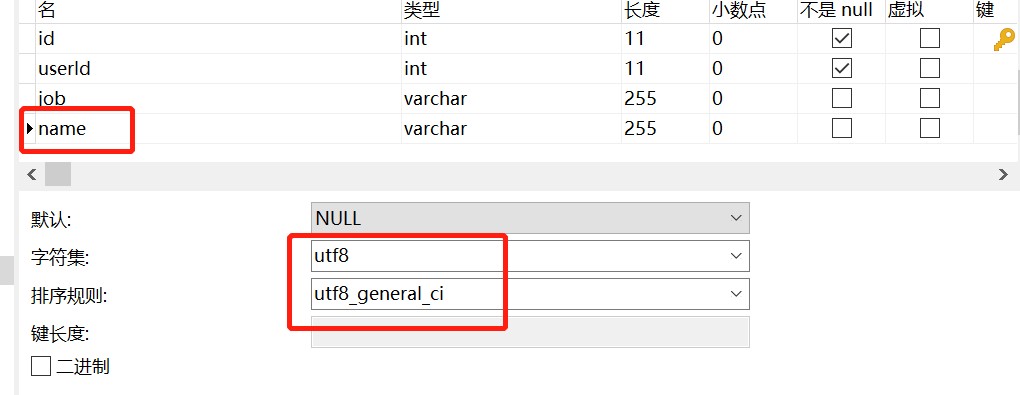
CREATE TABLE `user_job` (
`id` int(11) NOT NULL,
`userId` int(11) NOT NULL,
`job` varchar(255) DEFAULT NULL,
`name` varchar(255) DEFAULT NULL,
PRIMARY KEY (`id`),
KEY `idx_name` (`name`) USING BTREE
) ENGINE=InnoDB DEFAULT CHARSET=utf8;user 表的name字段编码是utf8mb4,而user_job表的name字段编码为utf8。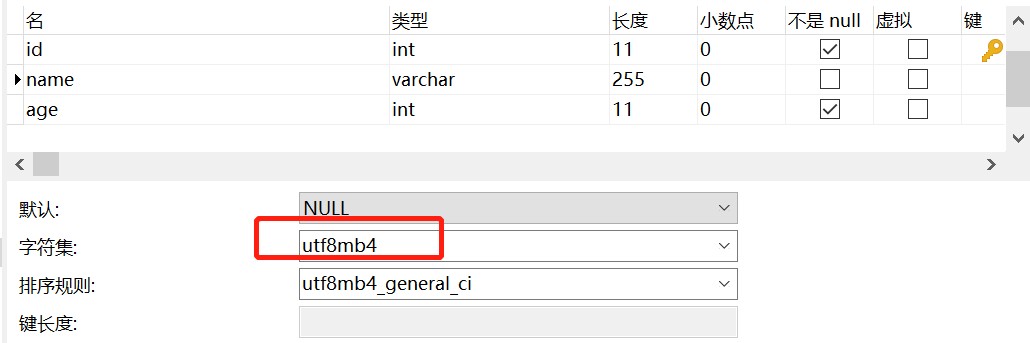
执行左外连接查询,user_job表还是走全表扫描,如下: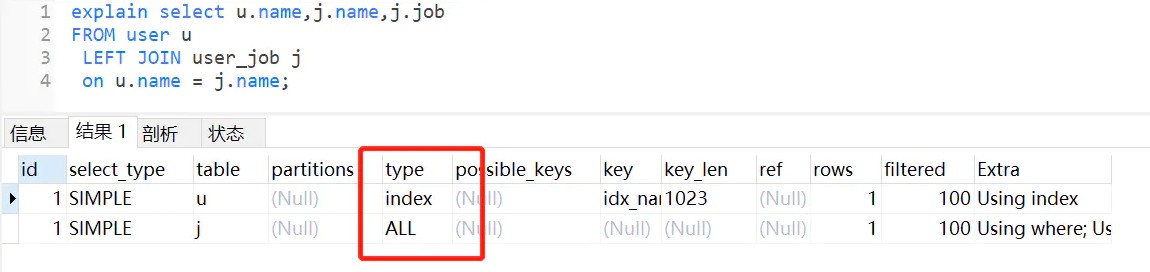
如果把它们改为name字段编码一致,还是会走索引。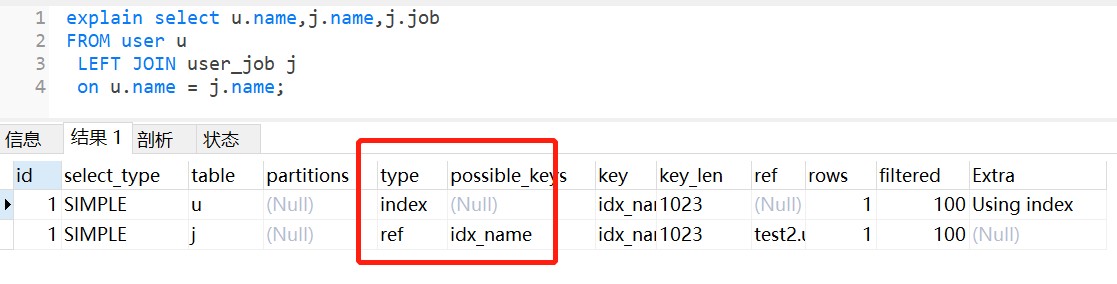
十、mysql估计使用全表扫描要比使用索引快,则不使用索引
当表的索引被查询,会使用最好的索引,除非优化器使用全表扫描更有效。优化器优化成全表扫描取决与使用最好索引查出来的数据是否超过表的30%的数据。
不要给’性别’等增加索引。如果某个数据列里包含了均是”0/1”或“Y/N”等值,即包含着许多重复的值,就算为它建立了索引,索引效果不会太好,还可能导致全表扫描。
Mysql出于效率与成本考虑,估算全表扫描与使用索引,哪个执行快。这跟它的优化器有关,来看一下它的逻辑架构图吧(图片来源网上)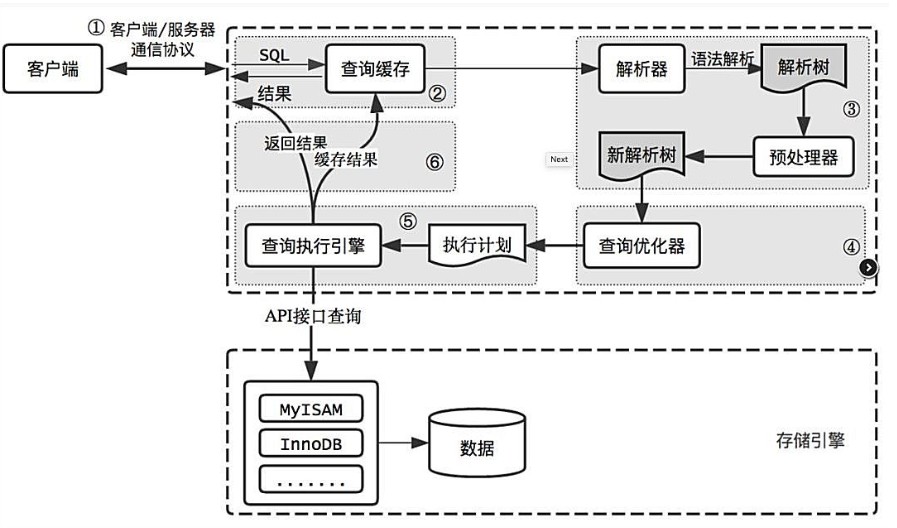
Example
模拟的表结构与肇事sql如下:
CREATE TABLE `user_session` (
`user_id` varchar(32) CHARACTER SET utf8mb4 NOT NULL,
`device_id` varchar(64) NOT NULL,
`status` varchar(2) NOT NULL,
`create_time` datetime NOT NULL,
`update_time` datetime DEFAULT NULL ON UPDATE CURRENT_TIMESTAMP,
PRIMARY KEY (`user_id`,`device_id`) USING BTREE
) ENGINE=InnoDB DEFAULT CHARSET=utf8;
explain
update user_session set status =1
where (`user_id` = '1' and `device_id`!='2')
or (`user_id` != '1' and `device_id`='2')分析
- 执行的sql,使用了or条件,因为组合主键(user_id,device_id),看起来像是每一列都加了索引,索引会生效。
- 但是出现!=,可能导致索引失效。也就是or+!=两大综合症,导致了慢更新sql。
解决方案
那么,怎么解决呢?我们是把or条件拆掉,分成两条执行。同时给device_id加一个普通索引。
最后,总结了索引失效的十大杂症,希望大家在工作学习中,参考这十大杂症,多点结合执行计划expain和场景,具体分析 ,而不是按部就班,墨守成规,认定哪个情景一定索引失效。


