数据类型

string
set key value时,redis会判断value能否转为int,能的话就encoding成int,不能就encoding成embstr。

计数器:INCR article:readcount:{文章id}→GET article:readcount:{文章id}
分布式系统全局序列号:INCRBY orderId 100
C语言,SDS(simple dynamic string)
- 二进制安全的数据结构
- 内存预分配机制,避免频繁的内存分配
- 兼容C函数库

hash
value又是一个map结构,也就是 <key1,<key2,value>>


一行数据只有一个字段经常变动的话推荐用hash。

list


应用场景:微博、微信公号消息流,用LPUSH msg:{用户-ID} 消息ID和LRANGE msg:{用户-ID} start stop实现
ziplist底层源码:

set

应用场景:


集合操作实现微博微信关注模型
zset


源码
typedef struct redisDb {
dict *dict; /* The keyspace for this DB */
dict *expires; /* Timeout of keys with a timeout set */
dict *blocking_keys; /* Keys with clients waiting for data (BLPOP)*/
dict *ready_keys; /* Blocked keys that received a PUSH */
dict *watched_keys; /* WATCHED keys for MULTI/EXEC CAS */
int id; /* Database ID */
long long avg_ttl; /* Average TTL, just for stats */
} redisDb;底层是以dict存储键值对的,键空间的键也就是数据库键,都是字符串对象,值可以是字符串对象、列表对象、哈希表对象、集合对象和有序集合对象中的任意一种。键的增加、删除、更新、读取都是对键空间的操作,不同的命令会执行不通的代码,最终都是在键空间上进行一系列操作。

/* Expand or create the hash table */
int dictExpand(dict *d, unsigned long size)
{
dictht n; /* the new hash table */
...
//如果已经在rehash过程中,不能expand
if (dictIsRehashing(d) || d->ht[0].used > size)
return DICT_ERR;
...
/* Allocate the new hash table and initialize all pointers to NULL */
n.table = zcalloc(realsize*sizeof(dictEntry*));
/* Is this the first initialization? If so it's not really a rehashing
* we just set the first hash table so that it can accept keys. */
if (d->ht[0].table == NULL) {
d->ht[0] = n;
return DICT_OK;
}
/* Prepare a second hash table for incremental rehashing */
d->ht[1] = n;
d->rehashidx = 0;
return DICT_OK;
}扩充空间的时候没有直接rehash,具体执行rehash的是dictRehash方法:
int dictRehash(dict *d, int n) {
int empty_visits = n*10; /* Max number of empty buckets to visit. */
if (!dictIsRehashing(d)) return 0;
while(n-- && d->ht[0].used != 0) {
dictEntry *de, *nextde;
/* Note that rehashidx can't overflow as we are sure there are more
* elements because ht[0].used != 0 */
//由rehashidx来标记搬运到了第几个元素
assert(d->ht[0].size > (unsigned long)d->rehashidx);
while(d->ht[0].table[d->rehashidx] == NULL) {
d->rehashidx++;
if (--empty_visits == 0) return 1;
}
de = d->ht[0].table[d->rehashidx];
/* Move all the keys in this bucket from the old to the new hash HT */
//每个桶关联了一个链表
while(de) {
unsigned int h;
nextde = de->next;
/* Get the index in the new hash table */
h = dictHashKey(d, de->key) & d->ht[1].sizemask;
de->next = d->ht[1].table[h];
d->ht[1].table[h] = de;
d->ht[0].used--;
d->ht[1].used++;
de = nextde;
}
d->ht[0].table[d->rehashidx] = NULL;
d->rehashidx++;
}
/* Check if we already rehashed the whole table... */
if (d->ht[0].used == 0) {
zfree(d->ht[0].table);
d->ht[0] = d->ht[1];
_dictReset(&d->ht[1]);
d->rehashidx = -1;
return 0;
}
/* More to rehash... */
return 1;
}redis提供了_dictRehashStep方法:
static void _dictRehashStep(dict *d) {
if (d->iterators == 0) dictRehash(d,1);
}在“合适”的地方渐进地调用这个_dictRehashStep,就实现了渐进式Rehash!就是实际对hashtable的数据有操作的地方,lookup or update operation。


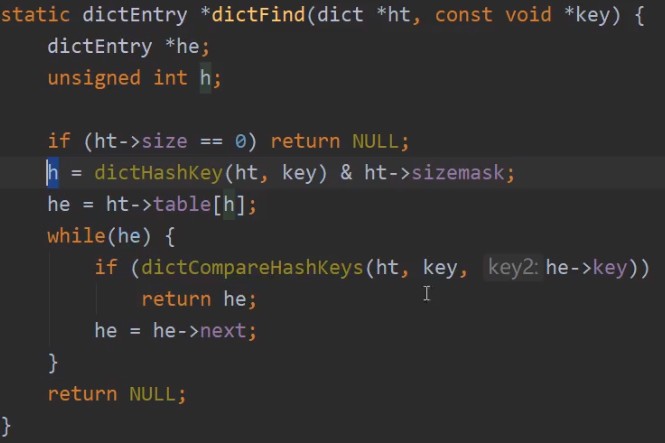
拉链法解决的hash冲突,那么在数据过多时,hash冲突不可避免,为了避免链表太长,直接进行rehash。rehash:Redis 默认使用了两个全局哈希表:哈希表 1 和哈希表 2。一开始,当你刚插入数据时,默认使用哈希表 1,此时的哈希表 2 并没有被分配空间。随着数据逐步增多,Redis 开始执行 rehash,这个过程分为三步:给哈希表 2 分配更大的空间,例如是当前哈希表 1 大小的两倍;把哈希表 1 中的数据重新映射并拷贝到哈希表 2 中;释放哈希表 1 的空间。到此,我们就可以从哈希表 1 切换到哈希表 2,用增大的哈希表 2 保存更多数据,而原来的哈希表 1 留作下一次 rehash 扩容备用。
这个过程看似简单,但是第二步涉及大量的数据拷贝,如果一次性把哈希表 1 中的数据都迁移完,会造成 Redis 线程阻塞,无法服务其他请求。此时,Redis 就无法快速访问数据了。为了避免这个问题,Redis 采用了渐进式 rehash。简单来说就是在第二步拷贝数据时,Redis 仍然正常处理客户端请求,每处理一个请求时,从哈希表 1 中的第一个索引位置开始,顺带着将这个索引位置上的所有 entries 拷贝到哈希表 2 中;等处理下一个请求时,再顺带拷贝哈希表 1 中的下一个索引位置的 entries。redis也会每秒扫描一下未迁移的数据,防止一直不被访问就无法迁移到新hash表。
RDB持久化机制
Redis DataBase
在指定的时间间隔内将内存中的数据集快照写入磁盘,实际操作过程是fork一个子进程,先将数据集写入临时文件,写入成功后,再替换之前的文件,用二进制压缩技术存储。
优点
- 整个Redis数据库将只包含一个文件 dump.rdb ,方便持久化
- 容灾性好,方便备份
- 性能最大化,fork子进程来完成子操作,让主进程继续处理命令,所以是IO最大化。使用单独子进程进行持久化,主进程不会进行任何IO操作,保证了redis的高性能
- 相对于数据集大时,比AOF的启动效率更高
缺点
- 数据安全性低。RDB 是间隔一段时间进行持久化,如果持久化之间 redis 发生故障,会发生数据丢失。更适合数据要求不严谨的时候
- 由于RDB是通过fork子进程来协助完成数据持久化工作,因此当数据集较大时,可能导致整个服务器停止服务几百毫秒,甚至一分钟。
AOF持久化机制
Append Only File
以日志的形式记录服务器所处理的每一个写、删除操作,查询操作不会记录,以文本方式记录,有点类似binlog
优点
- 数据安全,Redis中提供了三种同步策略:每秒同步、每修改同步和不同步。每秒同步是异步同步,效率高,但一旦宕机,这一秒内的修改数据将会丢失。每修改同步可以视为同步持久化,即每次发生的数据变化都会被立即记录到磁盘中
- 通过append 模式写文件,即使中途宕机也不会破坏已存在的内容,可以通过redis-check-aof 工具解决数据一致性问题
- AOF机制的 rewrite 模式。定期对AOF文件进行重新,压缩大小
缺点
- AOF文件比RDB文件大,且恢复速度慢
- 数据集大时,比RDB启动效率低
- 运行效率没RDB高,因为RDB时快照,AOF是同步策略
总结
AOF文件比RDB更新频率高,优先使用AOF还原数据。
AOF比RDB更安全更大
RDB性能比AOF好
如果两个都配优先加载AOF
为什么redis用跳表不用红黑树
跳表有五种操作,插入删除,查找,有序输出所有元素,按照范围区间查找元素,比如[100,600]的元素。红黑树范围查找效率没有跳表高。树的插入删除也比跳表实现复杂。
redis安装和配置文件redis.conf
https://www.cnblogs.com/xrq730/p/8890896.html
redis key 键名称中的冒号
redis中key的命名,用:分隔不同的层次|命名空间,如:user:id12345:contact
如果某个对象有字段的字段,用 . 连接。如user:id12345:contact.mail
其他分隔符
读过文首三个链接会发现以下格式的ID:user:id12345:contact 表示user表的ID为id12345的记录的字段contact。(那这个key的值就是对应的字段的值了)user::id12345::contact或user:::id12345:::contact,即多层冒号分隔。
user/id12345/contact
使用多层冒号分隔、使用/分隔,我测试过后,都可以正常获取key的值。
但是,在RedisDesktopManager这款Redis可视化管理工具中,只有使用单个:分隔的key名称,层次看起来最舒服。
另外redis官网也是介绍的冒号:,所以key名称的层次分隔符就推荐单个冒号:
最后一个字段contact,如果联系方式包含三种:tel, mail, qq,怎么命名?
官网说可以使用.或-连接,如:user:id12345:contact.mail或user.id12345.contact-mail表示用户表中ID为id12345的记录的contact属性中的mail属性值。
Redis过期键的删除策略
惰性过期
只有当访问一个key时,才会判断该key是否已经过期,过期则清除。该策略最大化节约cpu资源,但对内存非常不友好。
定期过期
每100ms扫描20个key(配置文件配置的),删除过期的,如果25%的过期了,就继续扫描删除操作。4.0之前会阻塞主进程,4.0之后可以选择异步执行。如果有大量的key同时过期了,就会阻塞住。
定时过期
给每一个key设定一个定时器,当这个key过期的时候由这个定时器删掉。对内存非常友好,但对cpu不友好。
redis中同时使用了惰性过期和定期过期两种过期策略
Redis线程模型、单线程快的原因
Redis基于Reactor模式开发了网络事件处理器,这个处理器叫做文件时间处理器 file event handler。这个文件事件处理器,它是单线程的,所有Redis 才叫做单线程模型,它采用IO多路复用机制来同时监听多隔Socket,根据Socket上的事件类型来选择对应的事件处理器来处理这个事件。可以实现高性能的网络通信模型,又可以根据内部其他单线程的模型进行对接,保证了简单性。
文件事件处理器结构包含4个部分:多个Socket,IO多路复用程序,文件事件分派器以及事件处理器(命令请求处理器、命令回复处理器、连接应答处理器等)。
多个Socket可能并发的产生不同的操作,每个操作对应不同的文件事件,但是IO多路复用程序会监听多个Socket,会将Socket放入一个队列中排队,每次从队列中取出一个Socket给事件分派器,事件分派器把Socket给对应的事件处理器。
然后一个Socket的事件处理完之后,IO多路复用程序才会将队列中的下一个Socket给时间分派器。
单线程快的原因
- 纯内存操作
- 核心是基于非阻塞的IO多路复用机制
- 单线程反而避免了多线程频繁上下文切换带来的性能问题
Redis为什么单线程
因为redis没有磁盘操作,一般都是在io操作时才会多线程,而redis是内存存储,切换线程反而更耗时。b+树也是磁盘操作,所以使用跳表而不是b+树。那么redis瓶颈在哪里?两个地方,内存大小,因为关系到存储的数据量,第二个是网络带宽,因为redis客户端服务端可能不在一个机器上。
大key问题
如果是单个对象非常大:可以尝试将对象分拆成几个key-value, 使用multiGet获取值,这样分拆的意义在于分拆单次操作的压力,将操作压力平摊到多个redis实例中,降低对单个redis的IO影响;如果是set和list存储的元素非常多,可以根据元素类型分类,把key分散到许多集群中。
redis的lfu算法
有些数据以前经常被访问到,只是最近的时间内没有被访问到,这样就导致这些数据很可能被淘汰掉,这样一来就会出现误判而淘汰热点数据。
所以有lfu(Least Frequently Used):最近频繁被使用。根据key最近被访问的频率进行淘汰。
缓存雪崩、击穿、穿透
缓存雪崩
缓存同一时间大面积失效,后面请求都落到数据库上导致数据库崩掉。(缓存重启也会)
解决方案:
- 缓存数据的过期事件设置随机,防止同一时间大量数据过期现象发生
- 给每一个缓存数据增加相应的缓存标记,记录缓存是否失效,如果标记失效则更新缓存(比较消耗性能)
- 缓存预热(面对重启)
- 互斥锁(避免大量请求对同一个键进行操作,让请求排队)
缓存击穿
缓存中没有但数据库中有的数据(一般是缓存时间到期),这时由于并发用户特别多,同时读取缓存没读到数据,又同时去数据库读。并发查同一条数据。
解决方案:
- 设置热点数据永不过期
- 加互斥锁
缓存穿透
缓存和数据库中都没有的数据,导致所有的请求都落到数据库上
解决方案:
- 接口层增加违规校验,如用户鉴权校验,id做基础校验,id <= 0 的直接拦截
- 从缓存取不到的数据,再数据库中也没取到,也可以将key-value对也为key-null,缓存有效时间可以设置短点,如30秒(太长会导致正常情况也无法使用),防止攻击用户反复用同一个id暴力攻击
- 采用布隆过滤器,将所有可能存在的数据哈希到一个足够大的bitmap中,一定不存在的数据会被这个bitmap拦截,避免对底层存储系统的查询压力
pipeline和lua有什么区别
当多个redis命令之间没有依赖、顺序关系(例如第二条命令依赖第一条命令的结果)时,建议使用pipline;如果命令之间有依赖或顺序关系时,pipline就无法使用,此时可以考虑采用lua脚本的方式来使用。pipeline不是原子的,lua是原子的,都不能回滚。
为什么不支持回滚
对于语法错误,事务将不会被提交。
对于运行时错误,只有对某个键执行不符合其类型的命令时才会发生,也就是程序代码错误,这种错误只有在开发阶段才会发生,很少在生环境中发生。
因此,为了保持Redis的简单性,不提供回滚功能。
主从复制核心原理
- 从节点执行slaveof masterIp port保存主节点信息
- 从节点中的定时任务发现主节点信息,建立和主节点socket连接
- 建立连接后,主节点将所有数据发送给从节点
- 完成数据同步后,主节点就会持续的把写命令发送给从节点,保证主从数据一致
全量复制
- 从节点发送psync命令,psync runid offset(第一次runid为?,offset为-1)
- 主节点返回 FULLRESYNC runid offset
- 主节点启动bgsave命令fork子进程进行RDB持久化
- 主节点将RDB文件发送给从节点,到从节点加载数据完成之前,写命令写入缓存区
- 从节点清理本地数据并加载RDB,如果开启AOF会重新AOF
部分复制(增量复制)
- 复制偏移量:psync runid offset
- 复制积压缓冲区:主节点内部维护的一个固定长度的、FIFO队列,当主从节点offset的差距过大超过缓冲区长度时,无法执行部分复制,只能全量复制
- 服务器运行ID(runid):每个Redis节点都有运行ID,由节点在启动时自动生成,主节点会将自己的运行ID发送给从节点,从节点会将主节点的运行ID存起来。从节点Redis断开重连时根据运行ID来判断同步进度:
- 如果从节点保存的runid与主节点现在的runid相同,主节点会继续尝试使用部分复制(到底能不能部分复制还是看offset和复制积压缓冲区的情况)
- 如果从节点保存的runid和主节点不相同,说明从节点在断线前同步的Redis节点并不是当前的主节点,只能进行全量复制。
过程原理图

Redis高可用集群方案
Sentinel

弊端:1、单点写故障。2、选主时访问瞬断。3、单机redis容易达到性能瓶颈,数据量大持久化时间长。4、写瓶颈,顶多10w并发
Redis Cluster

Redis Cluster时一种服务端Sharding技术,3.0版本开始正式提供。利用了slot(槽)的概念,一共分成16384个槽。将请求发送到任意节点,接收到请求的节点会将查询请求发送到正确的节点上执行
方案说明:
- 通过哈希的方式,将数据分片,每个节点均分存储一定哈希槽(哈希值)区间的数据,默认分配了16384个槽位
- 每份数据分片会存储在多个互为主从的多节点上
- 数据写入先写主节点,再同步到从节点(支持配置为阻塞同步)
- 同一分片多个节点间的数据不保持强一致性
- 读取数据时,当客户端操作的key没有分配在该节点上时,redis会返回转向指令,指向正确的节点
- 扩容时需要把旧节点的数据迁移一部分到新节点
redis cluster架构下,每个redis都要开放两个端口好,比如一个6379,另一个16379。
16379用来进行节点间通信,也就是cluster bus的通信,用来进行故障检测、配置更新、故障转移授权。cluster bus用了另外一种二进制的协议,gossip协议,用以节点间进行高效的数据交换,占用更少的网络带宽和处理时间。
优点
- 无中心架构,支持动态扩容,对业务透明
- 具备Sentinel的监控和自动Failover(故障转移)能力
- 客户端不需要链接集群所有节点,连接集群中任何一个可用节点即可
- 高性能,客户端直连redis服务,免去proxy代理
缺点
- 运维复杂,数据迁移需要人工干预
- 只能使用0号数据库
- 不支持批量操作(pipeline管道操作)
- 分布式逻辑和存储模块耦合等
Redis Sharding
业界普遍使用的多Redis实例集群方法。其主要思想是采用哈希算法将Redis数据的key进行散列,通过hash函数,特定的key会映射到特定的Redis节点上。Java redis客户端驱动jedis,支持Redis Sharding功能,即ShardedJedis以及结合缓存池的ShardedJedisPool
优点
非常简单,服务器Redis实例彼此独立,每个Redis实例像服务器一样运行,非常容易线性扩展,系统的灵活性很强
缺点
- 由于sharding处理放到客户端,规模进一步扩大给运维带来挑战。
- 客户端sharding不支持动态增删节点。服务器Redis实例群拓扑结构有变化时,每个客户端都要更新调整。
- 连接不能共享,当应用规模增大时,资源浪费制约优化
分布式缓存寻址算法
- hash算法:根据key进行hash,适合固定分片数量的场景,减少或拓展分片时都要重新计算
- 一致性hash:将整个hash值的区间组织成闭合圆环,计算每台服务器的hasnh映射到圆环中。使用hash算法计算数据的hash值顺时针寻找,找到的第一个服务器就是数据存储的服务。新增或减少节点只影响逆时针最近的一个服务器;数据倾斜用虚拟节点解决
- hash slot:将数据与服务器隔离开,数据与slot映射,slot与服务器映射,数据进行hash决定存放的slot新增及删除节点时,将slot进行迁移即可
Redisson
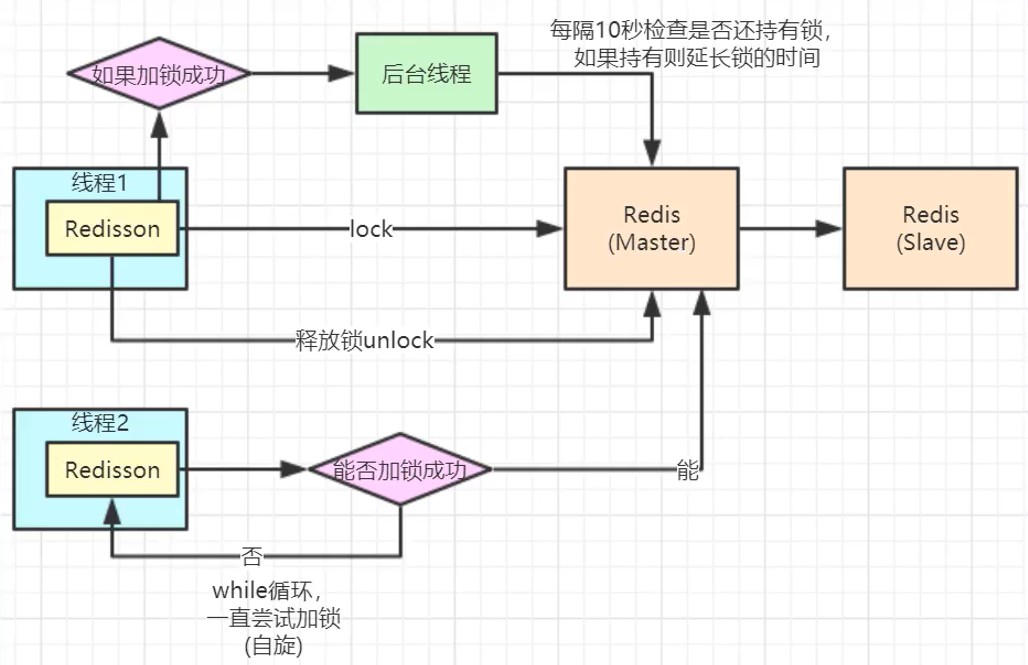
redisson核心代码:

lua原子命令,看门狗的默认超时时间是30s
回到上一层:

锁续命:


Redis事务实现
事务开始
MULTI命令的执行,标识着一个事务的开始。MULTI命令会将客户端状态的 flags 属性中打开 REDIS_MULTI标识来完成的。
命令入队
当一个客户端切换到事务状态之后,服务器会根据这个客户端发送来的命令来执行不同的操作。如果客户端发送的命令为MULTI、EXEC、WATCH、DISCARD中的一个,立即执行这个命令,否则将命令放入一个事务队列里面,然后向客户端返回QUEUED 回复。
如果客户端发送的是四个命令以外的命令,服务器并不立即执行。首先检查此命令格式是否正确,如果不正确服务器会在客户端状态(redisClient)的flags属性关闭 REDIS_MULTI 标识,并返回错误信息给客户端。如果正确将这个命令放入一个事务队列里,向客户端返回QUEUED回复。
事务队列是FIFO方式保存入队命令的
事务执行
客户端发送 EXEC 命令,服务器执行 EXEC 命令逻辑。
- 如果客户端状态的 flags 属性不包含 REDIS_MULTI 标识,或者包含 REDIS_DIRTY_CAS 或者 REDIS_DIRTY_EXEC 标识,直接取消事务执行。
- 否则处于事务状态,服务器会遍历客户端的事务队列,然后执行事务队列中的所有命令,最后将返回结果全部给客户端
redis不支持事务回滚机制,但是会检查每一个事务中的命令是否错误。
redis事务不支持检查那些程序员自己逻辑错误,例如String类型的数据库键执行HashMap操作
命令解释
- WATCH 命令是一个乐观锁,可以为Redis事务提供 check-and-set(CAS)行为。可以监控一个或多个键,一旦其中一个键被修改,之后的事务就不会执行,监控一直持续到EXEC命令。
- MULTI命令用于开启一个事务,总是返回OK。MULTI执行之后,客户端可以继续向服务器发送任意多条命令,这些命令不会立即被执行,而是放到一个队列中,当调用EXEC才会被执行。
- EXEC:执行所有事务块内的命令。返回事务块内所有命令的返回值,按命令执行的先后顺序排序。当操作打断返回null。
- 通过调用DISCARD,客户端可以清空事务队列,并放弃执行事务,并且客户端会从事务状态中退出。
- UNWATCH命令可以取消WATCH对所有key的监控。


