Zookeeper介绍
Zookeeper是一个高性能的分布式一致系统,在分布式系统中有着广泛的应用。基于它,可以实现分布式同步、配置管理、命名空间管理等众多功能,是分布式系统中常见的基础系统。
Zookeeper主要用来解决分布式集群中应用系统的一致性问题,它有着树状结构的节点,每个节点均可存储少量的数据。同时,用户可以修改和订阅节点中的内容。分布式系统中的节点通过监控这些数据状态的变化,从而可以达到基于数据的集群管理。
从设计模式角度来看,Zookeeper是基于观察者模式实现的。可以把它作为一个信息的中心。使用该服务的生产者和消费者都以Zookeeper中的数据为基准。即:
- 生产者可以改变Zookeeper的节点,或者节点上的数据
- 消费者通过订阅Zookeeper节点,从而能够在节点变动时收到通知
基于这样的机制,将Zookeeper作为信息中心,便可以实现分布式系统中节点状态的最终一致性。
Zookeeper具有以下特点:
- 最终一致性:客户端不论连接到哪个Zookeeper的哪一个节点,都会收到同一份状态。这是zookeeper最重要的性能。
- 可靠性:Zookeeper集群具有简单、健壮、良好的性能,如果消息m被到一台server接受,那么它将被所有的server接受。
- 实时性:Zookeeper保证client将在一个时间间隔范围内获得server的更新信息,或者server失效的信息。但由于网络延时等原因,Zookeeper不能保证两个client能同时得到刚更新的数据,如果需要最新数据,应该在读数据之前调用sync()接口。
- 等待无关(wait-free):慢的或者失效的client不得干预快速的client的请求,使得每个client都能有效的等待。
- 原子性:更新只能成功或者失败,没有中间状态。
- 顺序性:包括全局有序和偏序两种:全局有序是指如果在一台server上消息a在消息b前发布,则在所有Server上消息a都将在消息b前被发布;偏序是指如果一个消息b在消息a后被同一个发送者发布,a必将排在b前面。
zookeeper应用场景
数据发布与订阅:应用配置集中到节点上,应用启动时主动获取,并在节点上注册一个watcher,每次配置更新都会通知到应用。
命名服务:分布式命名服务,创建一个节点后,节点的路径就是全局唯一的,这个路径可以作为全局名称使用。一些分布式服务框架(RPC,RMI)中的服务地址列表,通过使用命名服务,客户端应该能够根据特定的命中来获取资源的实体、服务地址和提供者信息等
分布式通知/协调:不同的系统都监听同一个节点,一旦有了更新,另一个系统能够收到通知。
分布式锁:Zookeeper能保证数据的强一致性,用户任何时候都可以相信集群中每个节点的数据都是相同的。一个用户创建一个节点作为锁,另一个用户检测该节点,如果存在,代表别的用户已经锁住,如果不存在,则可以创建一个节点,代表拥有一个锁。
集群管理:包括集群监控和集群控制,就是监控集群机器状态,剔除集群和加入机器。zookeeper可以方便集群机器的管理,它可以实时监控znode节点的变化,一旦发现有机器挂了,该机器就会与zk断开连接,对应的临时目录节点会被删除,其他所有机器都收到通知。新机器加入类似,如图:
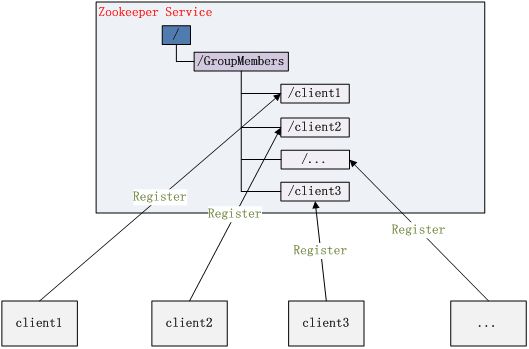
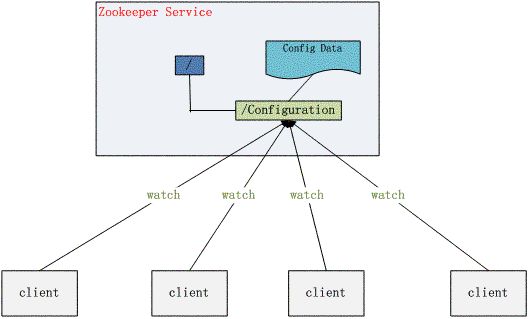
配置管理:在分布式应用环境中很常见,例如同一个应用系统需要多台节点运行,但是它们运行的应用系统的某些配置项是相同的,如果要修改这些相同的配置项,那么就必须同时修改每台运行这个应用系统的.properties或者xml配置,这样非常麻烦而且容易出错。
像这样的配置信息完全可以交给 Zookeeper 来管理,将配置信息保存在 Zookeeper 的某个目录节点中,然后将所有需要修改的应用机器监控配置信息的状态,一旦配置信息发生变化,利用watcher通知给各个客户端,从而修改配置。如图:
ZK的数据模型和节点类型
zk采用事务日志及快照文件的方案来落盘数据,保障数据在不丢失的情况下能快速恢复。
Znode
Znode兼具文件和目录两种特点,可以做路径标识,也可以存储数据,并可以具有子Znode。具有增删改查等操作。
Znode具有原子性操作,读操作一次性获取与节点相关的所有数据,写操作也将替换掉节点的所有数据。每一个节点都有自己的访问控制表,这个表规定了用户的权限。
Znode存储数据大小有限制。每个Znode数据大小之多1M。
Znode通过路径引用,如同Unix中的文件路径。路径必须是绝对的,唯一的。
Znode节点类型
- 持久节点:一旦创建,该数据节点会一直存储在zk服务器上,即使创建该节点的客户端与服务端的会话关闭了节点也不会删除
- 临时节点:当创建该节点的客户端会话因超时或发生异常而关闭时,该节点也相应的在zk上被删除。
- 有序节点:不是一种单纯种类的节点,而是在持久节点和临时节点的基础上,增加了一个节点有序的性质。
Zookeeper watch机制
客户端,可以通过在Znode上设置watch,实现实时监听znode的变化
watch事件是一个一次性的触发器,当被设置了watch的数据发生了变化的时候,则服务器将这个改变发送给设置了watch的客户端
- 父节点的创建、修改、删除都会出发watcher事件
- 子节点的创建,删除会触发watcher事件
一次性:一旦被触发就会移除,再次使用需要重新注册,因为每次变动都需要通知所有客户端
轻量:只通知发生了事件,不告知事件内容,减轻服务器和带宽压力
三个角色
watcher机制包括三个角色:客户端线程、客户端的watch manager以及zookeeper服务器
- 客户端向zookeeper服务器注册一个watcher监听
- 把这个监听信息存储到客户端的WatchManager中
- 当zookeeper中的节点发生变化时,会通知客户端,客户端会调用相应watcher对象中的回调方法。watch回调时串行同步的(FIFO)
ZAB协议
ZAB协议是为Zookeeper专门设计的一种支持崩溃恢复的原子广播协议,实现分布式数据一致性。
所有客户端的请求都写入到Leader进程中,然后,由Leader同步到其他节点Follower。
ZAB协议包括两种基本模式:崩溃恢复和消息广播。
消息广播
集群中所有事务请求都由Leader节点处理,Leader将客户端的事务请求转换为事务Proposal,并分发给集群中的所有Follower。
完成广播后,Leader等Follower反馈,当有过半数的Follower反馈消息后,Leader将再次向Follower广播Commit信息,确认之前的Proposal提交。(有点像2PC)
Leader节点的写入是一个两步操作,第一步是广播事务操作,第二步时广播提交操作,其中过半数指的是反馈节点数 >= N/2 + 1,N是全部Follower节点数。
崩溃恢复
以下状态进入崩溃恢复:
- 初始化集群,刚刚启动的时候
- Leader崩溃,故障宕机
- Leader失去了半数机器支持,与集群中超过一半的节点断连
此时开启新一轮Leader选举,选举产生的Leader会与过半的Follower进行同步,强一致性(CP),当与过半机器同步完成后,推出恢复模式,进入消息广布模式
整个Zookeeper集群的一致性保证都是在以上两个状态之间切换。
ZAB节点的三种状态
following:服从leader的命令(从节点,负责读)
leading:负责协调事务(主节点)
election/looking:选举状态
Zxid
ZAB协议的一个事务编号,一次事务意味着出现了一次选举,Zxid是一个64位的数字,其中低32位是一个简单的单调递增计数器,针对客户端每一个事务请求,计数器加1;而高32位则代表Leader周期年代编号。
Leader周期(epoch),每当一个新的leader选举出来,会从这个leader服务器上取出本地日志中最大事务的Zxid并从中读取epoch值,然后加1作为新的周期ID。
高32位代表每代Leader的唯一性,低32位代表了每代Leader中事务的唯一性。
分布式锁的流程
分布式锁的应用上面已经讲到了,具体流程如下:
假如说有n个分布式的工作点,定义为a1,a2,a3,a4……
当某个分布式点做一件事时,先去zk某个固定位置判断(例如:/aTask/sync目录下)是否存在一个特定节点(例如节点名:lock):
- 如果没有,则创建该节点,即声明自己持有该锁。然后进行分布式任务,任务结束后。去删除该节点,表明释放该锁。
- 如果有,表明其他工作点持有了锁,不能开展分布式任务。
分布式锁的应用
举一个最简单的例子:
1、假如有一个系统,能够提供报表查看功能——>于是我们开发了一个单节点应用
2、该系统访量非常大,系统难以支撑——>我们部署了多个节点(加入为5个),分担访问请求。于是成了分布式应用
3、老板要求增加一个每天晚上向指定邮件发送该日统计报表的功能—–>应用中增加个定时线程,每天晚上半夜跑报表,发邮件
这个时候,出问题了,老板每天晚上会收到5封邮件!因为同样的程序我们部署了5个节点!怎么解决呢?
方案一:有一个节点和其他节点不一样,具有每日汇总功能。
优点:开发简单。
缺点:这样,一个应用便成了两个应用。我们必须维护两份代码。一份是不具有每日汇总功能的,一份是具有每日汇总功能的。
方案二:增加分布式锁。这样,5个节点中,只有获取到锁的节点才会发出邮件。
优点:代码还是只有一份,维护简单。扩展性强,可以继续扩展类似的需要锁的功能(例如某个业务流程只允许处理一次,还可以继续复用相关逻辑)。
缺点:开发稍微复杂一点。
因此,方案二是最好的选择。
基于ZooKeeper的三种分布式锁实现
https://www.cnblogs.com/codestory/p/11387116.html
zookeeper安装
# 版本信息:3.5.8
# 路径:/home/rndii/projects/zookeeper/apache-zookeeper-3.5.8
# 服务器节点:10.0.1.104 10.0.1.117 10.0.1.127
# 操作系统用户:rndii
# 1.修改zoo.conf文件,如果该文件不存在,则cp zoo.simple.cnf zoo.cnf
# zoo.cnf 如下修改:
# The number of milliseconds of each tick
tickTime=2000
# The number of ticks that the initial
# synchronization phase can take
initLimit=10
# The number of ticks that can pass between
# sending a request and getting an acknowledgement
syncLimit=5
# the directory where the snapshot is stored.
# do not use /tmp for storage, /tmp here is just
# example sakes.
dataDir=/home/rndii/projects/zookeeper/apache-zookeeper-3.5.8/data
# the port at which the clients will connect
clientPort=2181
# the maximum number of client connections.
# increase this if you need to handle more clients
#maxClientCnxns=60
#
# Be sure to read the maintenance section of the
# administrator guide before turning on autopurge.
#
# http://zookeeper.apache.org/doc/current/zookeeperAdmin.html#sc_maintenance
#
# The number of snapshots to retain in dataDir
#autopurge.snapRetainCount=3
# Purge task interval in hours
# Set to "0" to disable auto purge feature
#autopurge.purgeInterval=1
server.1=10.0.1.104:2888:3888
server.2=10.0.1.117:2888:3888
server.3=10.0.1.127:2888:3888
# 配置文件到此结束
# 2.在data文件夹中新增myid文本文件,内容为对应ip的节点id。对应zoo.cnf下的server.x=10.0.1.104:2888:3888的x
# 3.如果未配置全局环境变量可修改zoo下的bin/zkServer.sh文件增加JAVA_HOME=xx
# 4. 常规命令
# 启动
bin/zkServer.sh start
# 停止
bin/zkServer.sh stop
# 查看zookeeper的状态
bin/zkServer.sh status

