Elasticsearch 集群架构
转载至阿里云:https://zhuanlan.zhihu.com/p/32990496
Elasticsearch的详细介绍可以到官网查看。我们先来看一下Elasticsearch中几个关键概念:
- 节点(Node):物理概念,一个运行的Elasticearch实例,一般是一台机器上的一个进程。
- 索引(Index),逻辑概念,包括配置信息mapping和倒排正排数据文件,一个索引的数据文件可能会分布于一台机器,也有可能分布于多台机器。索引的另外一层意思是倒排索引文件。
- 分片(Shard):为了支持更大量的数据,索引一般会按某个维度分成多个部分,每个部分就是一个分片,分片被节点(Node)管理。一个节点一般会管理多个分片,这些分片可能是属于同一份索引,也有可能属于不同索引,但是为了可靠性和可用性,同一个索引的分片尽量会分布在不同节点上。分片有两种,主分片和副本分片。
- 副本(Replica):同一个分片(Shard)的备份数据,一个分片可能会有0个或多个副本,这些副本中的数据保证强一致或最终一致。
用图形表示出来可能是这样子的:
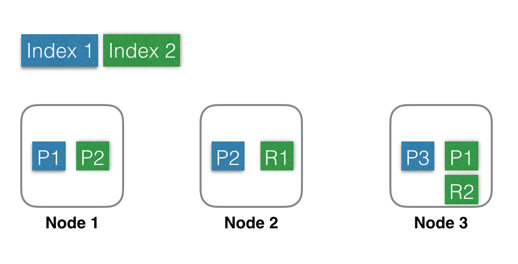
- Index 1:蓝色部分,有3个shard,分别是P1,P2,P3,位于3个不同的Node中,这里没有Replica。
- Index 2:绿色部分,有2个shard,分别是P1,P2,位于2个不同的Node中。并且每个shard有一个replica,分别是R1和R2。基于系统可用性的考虑,同一个shard的 primary 和 replica 不能位于同一个Node中。这里Shard1的P1和R1分别位于Node3和Node2中,如果某一刻Node2发生宕机,服务基本不会受影响,因为还有一个P1和R2都还是可用的。因为是主备架构,当主分片发生故障时,需要切换,这时候需要选举一个副本作为新主,这里除了会耗费一点点时间外,也会有丢失数据的风险。
建Index流程
建索引(Index)的时候,一个Doc先是经过路由规则定位到主Shard,发送这个doc到主Shard上建索引,成功后再发送这个Doc到这个Shard的副本上建索引,等副本上建索引成功后才返回成功。
在这种架构中,索引数据全部位于Shard中,主Shard和副本Shard各存储一份。当某个副本Shard或者主Shard丢失(比如机器宕机,网络中断等)时,需要将丢失的Shard在其他Node中恢复回来,这时候就需要从其他副本(Replica)全量拷贝这个Shard的所有数据到新Node上构造新Shard。这个拷贝过程需要一段时间,这段时间内只能由剩余主副本来承载流量,在恢复完成之前,整个系统会处于一个比较危险的状态,直到failover结束。
这里就体现了副本(Replica)存在的一个理由,避免数据丢失,提高数据可靠性。副本(Replica)存在的另一个理由是读请求量很大的时候,一个Node无法承载所有流量,这个时候就需要一个副本来分流查询压力,目的就是扩展查询能力。
角色部署方式
看看角色分工的两种不同方式:
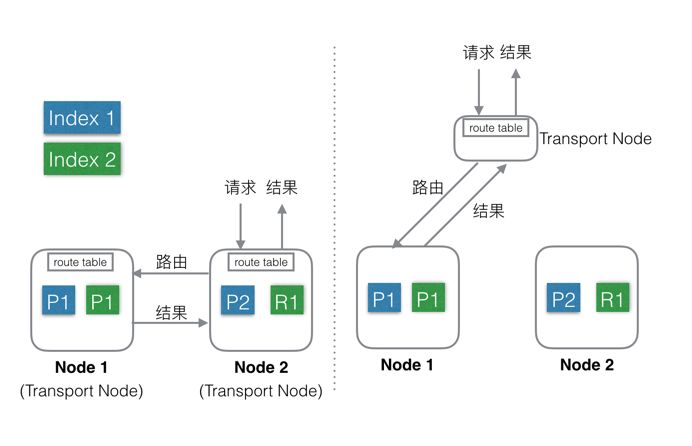
Elasticsearch支持上述两种方式:
混合部署(左图):
- 默认方式。
- 不考虑 MasterNode 的情况下,还有两种Node,Data Node 和 Transport Node ,这种部署模式下,这两种不同类型Node角色都位于同一个Node中,相当于一个Node具备两种功能:Data和Transport。
- 当有index或者query请求的时候,请求随机(自定义)发送给任何一个Node,这台Node中会持有一个全局的路由表,通过路由表选择合适的Node,将请求发送给这些Node,然后等所有请求都返回后,合并结果,然后返回给用户。一个Node分饰两种角色。
- 好处就是使用极其简单,易上手,对推广系统有很大价值。最简单的场景下只需要启动一个Node,就能完成所有的功能。
- 缺点就是多种类型的请求会相互影响,在大集群如果某一个 Data Node 出现热点,那么就会影响途经这个Data Node的所有其他跨Node请求。如果发生故障,故障影响面会变大很多。
- Elasticsearch中每个Node都需要和其余的每一个Node都保持13个连接。这种情况下,每个Node都需要和其他所有Node保持连接,而一个系统的连接数是有上限的,这样连接数就会限制集群规模。
- 还有就是不能支持集群的热更新。
分层部署(右图):
- 通过配置可以隔离开Node。
- 设置部分Node为Transport Node,专门用来做请求转发和结果合并。
- 其他Node可以设置为DataNode,专门用来处理数据。
- 缺点是上手复杂,需要提前设置好Transport的数量,且数量和Data Node、流量等相关,否则要么资源闲置,要么机器被打爆。
- 好处就是角色相互独立,不会相互影响,一般Transport Node的流量是平均分配的,很少出现单台机器的CPU或流量被打满的情况,而DataNode由于处理数据,很容易出现单机资源被占满,比如CPU,网络,磁盘等。独立开后,DataNode如果出了故障只是影响单节点的数据处理,不会影响其他节点的请求,影响限制在最小的范围内。
- 角色独立后,只需要Transport Node连接所有的DataNode,而DataNode则不需要和其他DataNode有连接。一个集群中DataNode的数量远大于Transport Node,这样集群的规模可以更大。另外,还可以通过分组,使Transport Node只连接固定分组的DataNode,这样Elasticsearch的连接数问题就彻底解决了。
- 可以支持热更新:先一台一台的升级DataNode,升级完成后再升级Transport Node,整个过程中,可以做到让用户无感知。
Elasticsearch 数据层架构
数据存储
Elasticsearch的Index和meta,目前支持存储在本地文件系统中,同时支持niofs,mmap,simplefs,smb等不同加载方式,性能最好的是直接将索引LOCK进内存的MMap方式。默认,Elasticsearch会自动选择加载方式,另外可以自己在配置文件中配置。这里有几个细节,具体可以看官方文档。
索引和meta数据都存在本地,会带来一个问题:当某一台机器宕机或者磁盘损坏的时候,数据就丢失了。为了解决这个问题,可以使用Replica(副本)功能。
副本(Replica)
可以为每一个Index设置一个配置项:副本(Replicda)数,如果设置副本数为2,那么就会有3个Shard,其中一个是PrimaryShard,其余两个是ReplicaShard,这三个Shard会被Mater尽量调度到不同机器,甚至机架上,这三个Shard中的数据一样,提供同样的服务能力。
副本(Replica)的目的有三个:
- 保证服务可用性:当设置了多个Replica的时候,如果某一个Replica不可用的时候,那么请求流量可以继续发往其他Replica,服务可以很快恢复开始服务。
- 保证数据可靠性:如果只有一个Primary,没有Replica,那么当Primary的机器磁盘损坏的时候,那么这个Node中所有Shard的数据会丢失,只能reindex了。
- 提供更大的查询能力:当Shard提供的查询能力无法满足业务需求的时候, 可以继续加N个Replica,这样查询能力就能提高N倍,轻松增加系统的并发度。
问题
上面说了一些优势,这种架构同样在一些场景下会有些问题。
Elasticsearch采用的是基于本地文件系统,使用Replica保证数据可靠性的技术架构,这种架构一定程度上可以满足大部分需求和场景,但是也存在一些遗憾:
- Replica带来成本浪费。为了保证数据可靠性,必须使用Replica,但是当一个Shard就能满足处理能力的时候,另一个Shard的计算能力就会浪费。
- Replica带来写性能和吞吐的下降。每次Index或者update的时候,需要先更新Primary Shard,更新成功后再并行去更新Replica,再加上长尾,写入性能会有不少的下降。
- 当出现热点或者需要紧急扩容的时候动态增加Replica慢。新Shard的数据需要完全从其他Shard拷贝,拷贝时间较长。
上面介绍了Elasticsearch数据层的架构,以及副本策略带来的优势和不足,下面简单介绍了几种不同形式的分布式数据系统架构。
分布式系统
第一种:基于本地文件系统的分布式系统
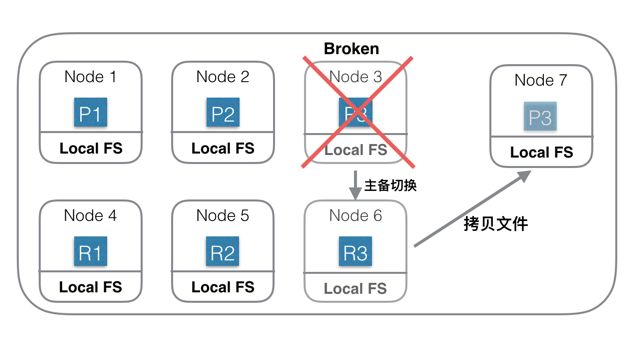
上图中是一个基于本地磁盘存储数据的分布式系统。Index一共有3个Shard,每个Shard除了Primary Shard外,还有一个Replica Shard。当Node 3机器宕机或磁盘损坏的时候,首先确认P3已经不可用,重新选举R3位Primary Shard,此Shard发生主备切换。然后重新找一台机器Node 7,在Node7 上重新启动P3的新Replica。由于数据都会存在本地磁盘,此时需要将Shard 3的数据从Node 6上拷贝到Node7上。如果有200G数据,千兆网络,拷贝完需要1600秒。如果没有replica,则这1600秒内这些Shard就不能服务。
为了保证可靠性,就需要冗余Shard,会导致更多的物理资源消耗。
这种思想的另外一种表现形式是使用双集群,集群级别做备份。
在这种架构中,如果你的数据是在其他存储系统中生成的,比如HDFS/HBase,那么你还需要一个数据传输系统,将准备好的数据分发到相应的机器上。
这种架构中为了保证可用性和可靠性,需要双集群或者Replica才能用于生产环境,优势和副作用在上面介绍Elasticsearch的时候已经介绍过了,这里就就不赘述了。
Elasticsearch使用的就是这种架构方式。
第二种:基于分布式文件系统的分布式系统(共享存储)
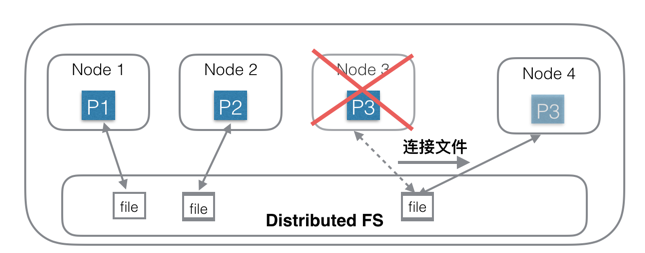
针对第一种架构中的问题,另一种思路是:存储和计算分离。
第一种思路的问题根源是数据量大,拷贝数据耗时多,那么有没有办法可以不拷贝数据?为了实现这个目的,一种思路是底层存储层使用共享存储,每个Shard只需要连接到一个分布式文件系统中的一个目录/文件即可,Shard中不含有数据,只含有计算部分。相当于每个Node中只负责计算部分,存储部分放在底层的另一个分布式文件系统中,比如HDFS。
上图中,Node 1 连接到第一个文件;Node 2连接到第二个文件;Node3连接到第三个文件。当Node 3机器宕机后,只需要在Node 4机器上新建一个空的Shard,然后构造一个新连接,连接到底层分布式文件系统的第三个文件即可,创建连接的速度是很快的,总耗时会非常短。
这种是一种典型的存储和计算分离的架构,优势有以下几个方面:
- 在这种架构下,资源可以更加弹性,当存储不够的时候只需要扩容存储系统的容量;当计算不够的时候,只需要扩容计算部分容量。
- 存储和计算是独立管理的,资源管理粒度更小,管理更加精细化,浪费更少,结果就是总体成本可以更低。
- 负载更加突出,抗热点能力更强。一般热点问题基本都出现在计算部分,对于存储和计算分离系统,计算部分由于没有绑定数据,可以实时的扩容、缩容和迁移,当出现热点的时候,可以第一时间将计算调度到新节点上。
这种架构同时也有一个不足:
访问分布式文件系统的性能可能不及访问本地文件系统。在上一代分布式文件系统中,这是一个比较明显的问题,但是目前使用了各种用户态协议栈后,这个差距已经越来越小了。
HBase使用的就是这种架构方式。
Solr也支持这种形式的架构。
Lucene数据模型
Lucene中包含了四种基本数据类型,分别是:
- Index:索引,由很多的Document组成。
- Document:由很多的Field组成,是Index和Search的最小单位。
- Field:由很多的Term组成,包括Field Name和Field Value。
- Term:由很多的字节组成,可以分词。
上述四种类型在Elasticsearch中同样存在,意思也一样。
Lucene中存储的索引主要分为三种类型:
- Invert Index:倒排索引,或者简称Index,通过Term可以查询到拥有该Term的文档。可以配置为是否分词,如果分词可以配置不同的分词器。索引存储的时候有多种存储类型,分别是:
- DOCS:只存储DocID。
- DOCS_AND_FREQS:存储DocID和词频(Term Freq)。
- DOCS_AND_FREQS_AND_POSITIONS:存储DocID、词频(Term Freq)和位置。
- DOCS_AND_FREQS_AND_POSITIONS_AND_OFFSETS:存储DocID、词频(Term Freq)、位置和偏移。
- DocValues:正排索引,采用列式存储。通过DocID可以快速读取到该Doc的特定字段的值。由于是列式存储,性能会比较好。一般用于sort,agg等需要高频读取Doc字段值的场景。
- Store:字段原始内容存储,同一篇文章的多个Field的Store会存储在一起,适用于一次读取少量且多个字段内存的场景,比如摘要等。
Lucene中提供索引和搜索的最小组织形式是Segment,Segment中按照索引类型不同,分成了Invert Index,Doc Values和Store这三大类(还有一些辅助类,这里省略),每一类里面都是按照Doc为最小单位存储。
- Invert Index中存储的Key是Term,Value是Doc ID的链表;
- Doc Value中Key 是Doc ID和Field Name,Value是Field Value;
- Store的Key是Doc ID,Value是Filed Name和Filed Value。
由于Lucene中没有主键概念和更新逻辑,所有对Lucene的更新都是Append一个新Doc,类似于一个只能Append的队列,所有Doc都被同等对等,同样的处理方式。其中的Doc由众多Field组成,没有特殊Field,每个Field也都被同等对待,同样的处理方式。
从上面介绍来看,Lucene只是提供了一个索引和查询的最基本的功能,距离一个完全可用的完整搜索引擎还有一些距离
Lucene => Elasticsearch
在Elasticsearch中,为了支持分布式,增加了一个系统字段_routing(路由),通过_routing将Doc分发到不同的Shard,不同的Shard可以位于不同的机器上,这样就能实现简单的分布式了。
采用类似的方式,Elasticsearch增加了_id、_version、_source和_seq_no等等多个系统字段,通过这些Elasticsearch中特有的系统字段可以有效解决上述的几个问题,新增的系统字段主要是下列几个:
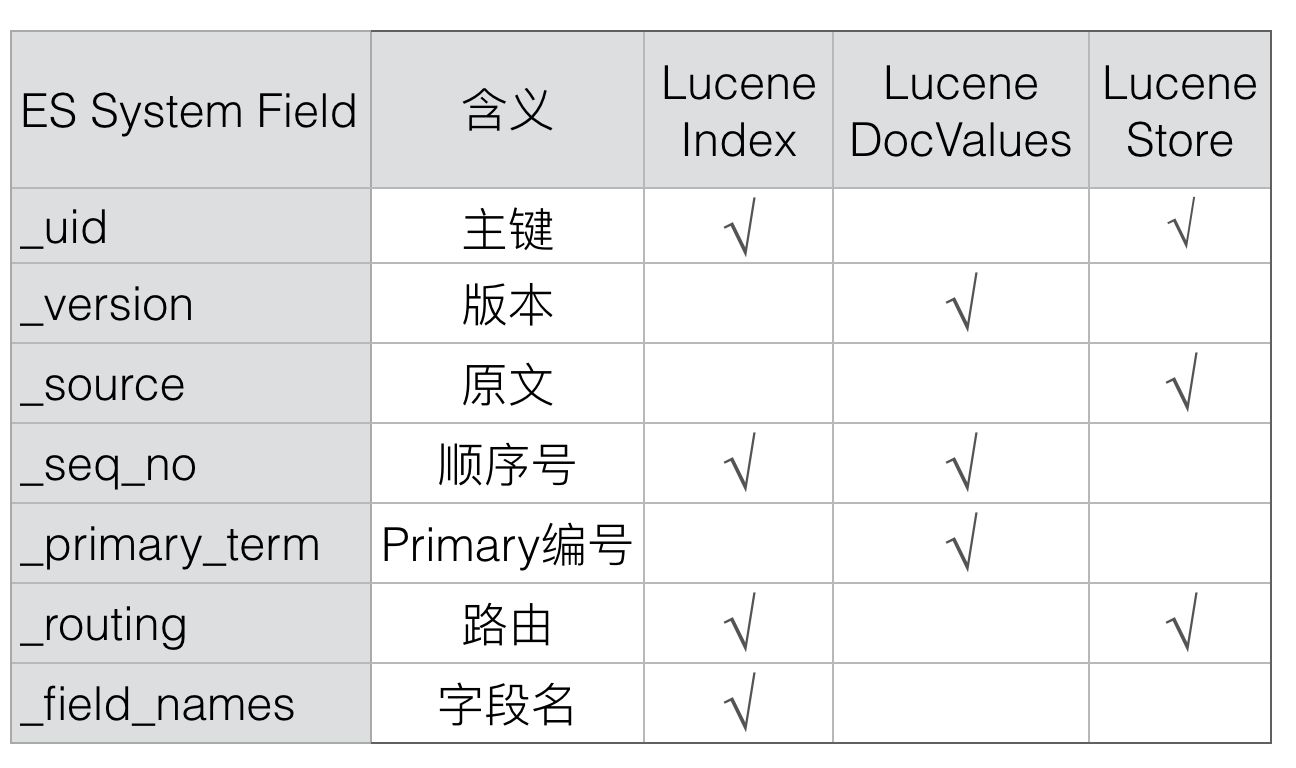
1. _id
Doc的主键,在写入的时候,可以指定该Doc的ID值,如果不指定,则系统自动生成一个唯一的UUID值。
Lucene中没有主键索引,要保证系统中同一个Doc不会重复,Elasticsearch引入了_id字段来实现主键。每次写入的时候都会先查询id,如果有,则说明已经有相同Doc存在了。
通过_id值(ES内部转换成_uid)可以唯一在Elasticsearch中确定一个Doc。
Elasticsearch中,_id只是一个用户级别的虚拟字段,在Elasticsearch中并不会映射到Lucene中,所以也就不会存储该字段的值。
_id的值可以由_uid解析而来(_uid =type + '#' + id),Elasticsearch中会存储_uid。
2. _uid
_uid的格式是:type + '#' + id。
_uid会存储在Lucene中,在Lucene中的映射关系如下:dex下可能存在多个id值相同的Doc,而6.0.0之后只支持单Type,同Index下id值是唯一的。
uid会存储在Lucene中,在Lucene中的映射关系如下:

_uid 只是存储了倒排Index和原文store:倒排Index的目的是可以通过_id快速查询到文档;原文store用来在返回的Response里面填充完整的_id值。
在Lucene中存储_uid,而不是_id的原因是,在6.0.0之前版本里面,_uid可以比_id表示更多的信息,比如Type。在6.0.0版本之后,同一个Index只能有一个Type,这时候Type就没多大意义了,后面Type应该会消失,那时候_id就会和_uid概念一样,到时候两者会合二为一,也能简化大家的理解。
3. _version
Elasticsearch中每个Doc都会有一个Version,该Version可以由用户指定,也可以由系统自动生成。如果是系统自动生成,那么每次Version都是递增1。
_version是实时的,不受搜索的近实时性影响,原因是可以通过_uid从内存中versionMap或者TransLog中读取到。
Version在Lucene中也是映射为一个特殊的Field存在。

Elasticsearch中Version字段的主要目的是通过doc_id读取Version,所以Version只要存储为DocValues就可以了,类似于KeyValue存储。
Elasticsearch通过使用version来保证对文档的变更能以正确的顺序执行,避免乱序造成的数据丢失。
4. _source
Elasticsearch中有一个重要的概念是source,存储原始文档,也可以通过过滤设置只存储特定Field。
Source在Lucene中也是映射为了一个特殊的Field存在:

Elasticsearch中_source字段的主要目的是通过doc_id读取该文档的原始内容,所以只需要存储Store即可。
_source其实是名为_source的虚拟Store Field。
Elasticsearch中使用_source字段可以实现以下功能:
- Update:部分更新时,需要从读取文档保存在
_source字段中的原文,然后和请求中的部分字段合并为一个完整文档。如果没有_source,则不能完成部分字段的Update操作。 - Rebuild:最新的版本中新增了rebuild接口,可以通过Rebuild API完成索引重建,过程中不需要从其他系统导入全量数据,而是从当前文档的
_source中读取。如果没有_source,则不能使用Rebuild API。 - Script:不管是Index还是Search的Script,都可能用到存储在Store中的原始内容,如果禁用了
_source,则这部分功能不再可用。 - Summary:摘要信息也是来源于
_source字段。
5. _seq_no
严格递增的顺序号,每个文档一个,Shard级别严格递增,保证后写入的Doc的_seq_no大于先写入的Doc的_seq_no。
任何类型的写操作,包括index、create、update和Delete,都会生成一个_seq_no。
_seq_no在Primary Node中由SequenceNumbersService生成,但其实真正产生这个值的是LocalCheckpointTracker,每次递增1:
/**
* The next available sequence number.
*/
private volatile long nextSeqNo;
/**
* Issue the next sequence number.
*
* @return the next assigned sequence number
*/
synchronized long generateSeqNo() {
return nextSeqNo++;
}每个文档在使用Lucene的document操作接口之前,会获取到一个_seq_no,这个_seq_no会以系统保留Field的名义存储到Lucene中,文档写入Lucene成功后,会标记该seq_no为完成状态,这时候会使用当前seq_no更新local_checkpoint。
checkpoint分为 local_checkpoint 和 global_checkpoint ,主要是用于保证有序性,以及减少Shard恢复时数据拷贝的数据拷贝量,更详细的介绍可以看这篇文章:Sequence IDs: Coming Soon to an Elasticsearch Cluster Near You。
_seq_no在Lucene中的映射:

Elasticsearch中_seq_no的作用有两个:
- 通过doc_id查询到该文档的seq_no,
- 通过seq_no范围查找相关文档,所以也就需要存储为Index和DocValues(或者Store)。
由于是在冲突检测时才需要读取文档的_seq_no,而且此时只需要读取_seq_no,不需要其他字段,这时候存储为列式存储的DocValues比Store在性能上更好一些。
_seq_no是严格递增的,写入Lucene的顺序也是递增的,所以DocValues存储类型可以设置为Sorted。
另外,_seq_no的索引应该仅需要支持存储DocId就可以了,不需要FREQS、POSITIONS和分词。如果多存储了这些,对功能也没影响,就是多占了一点资源而已。
6. _primary_term
_primary_term也和_seq_no一样是一个整数,每当Primary Shard发生重新分配时,比如重启,Primary选举等,_primary_term会递增1。
_primary_term主要是用来恢复数据时处理当多个文档的_seq_no一样时的冲突,避免Primary Shard上的写入被覆盖。

Elasticsearch中_primary_term只需要通过doc_id读取到即可,所以只需要保存为DocValues就可以了
7. _routing
路由规则,写入和查询的routing需要一致,否则会出现写入的文档没法被查到情况。
在mapping中,或者Request中可以指定按某个字段路由。默认是按照_Id值路由。
_routing在Lucene中映射为:

Elasticsearch中文档级别的_routing主要有两个目的:
- 可以查询到使用某种
_routing的文档有哪些,当发生_routing变化时,可以对历史_routing的文档重新读取再Index,这个需要倒排Index。 - 查询到文档后,在Response里面展示该文档使用的
_routing规则,这里需要存储为Store。
8. _field_names
该字段会索引某个Field的名称,用来判断某个Doc中是否存在某个Field,用于exists或者missing请求。
_field_names在Lucene中的映射:

Elasticsearch中_field_names的目的是查询哪些Doc的这个Field是否存在,所以只需要倒排Index即可。


