思考步骤
评估是否真的需要缓存
1.1 使用场景?有返回时间要求吗?
1.2 是否频繁?落到数据库压力大吗?
1.3 计算难度有多大?
真的需要缓存了
2.1 数据粒度?
2.2 数据类型?
2.3 数据大小?
2.4 数据有效时长?
2.5 加载进缓存的时机?
2.6 删除缓存的时机?
2.7 更新缓存的时机?根据多个缓存对缓存进行操作
3.1 缓存值可信吗?
3.2 为什么要根据缓存值对缓存操作?想要的是过程值还是结果值?
3.3 考虑过拿第一个缓存成功,拿第二个缓存成功,但是第一个缓存在第二个缓存操作的时候失效的情况和后果吗?
3.4 缓存联动管理是否困难?
简易操作缓存方案
- 使用饿汉模式进行管理。只有在要读的时候,才进行缓存加载,其他操作删除相关缓存。
- 缓存时间设置不宜过长,5分钟内为宜(因为现在业务没什么对数据库压力特别大、计算又很复杂的时候)
- 不同Key的缓存失效时间尽量随机
- 考虑缓存穿透问题
- 不要使用redis事务
- 先进行数据库操作,再操作缓存
- 数据粒度要很大时,借助定时任务定期刷新内存
- 缓存中找不到时,应该去查找数据库中是否存在,记得用一定策略保证击穿问题得到解决
- 用service屏蔽缓存的直接操作,避免造成缓存管理困难(因为service的操作一定可以反映到数据库上,直接操作缓存不一定能落到数据库)
ps: 数据一致性可以借助数据库事务进行实现,保证最坏结果是一次最近更新的值
补充规范
1:key定义的规范,这个是用的时候比较容易出错的,重名,和系统关键字冲突,长度等,都需要给出规范来
2:value上,应该控制数据的长度,比如防止一些大数据类型,redis本来是提速的,不要因为数据长度影响了自身性能,另外就是合理的使用数据类型,节省存储提升性能,比如能整型的就不要字符串型
3:提前评估生命周期,必须保证每个变量都有过期时间;需要对数据进行手动清理,打散过期时间,防止雪崩
4:尽可能只使用set和get,避免使用其他命令,特别是flushXXX
5:尽量不要使用事务,事务逻辑尽量通过对应的框架实现,包括分布式事务seata
6:做好防穿透,击穿,雪崩的常规逻辑处理,比如增加有效数据校验,防止数据库压力过大,增加互斥锁,降低并发,打乱过期时间等。
踩坑
原本是用RedisTemplate实现
建议每个函数还可以重载一个默认值的函数,不然每个函数都要写入太多的参数,一般除了KEY值外,其他的值,都可以根据规范来给一个默认的
还有封装的话最好用原生提供的jedis:
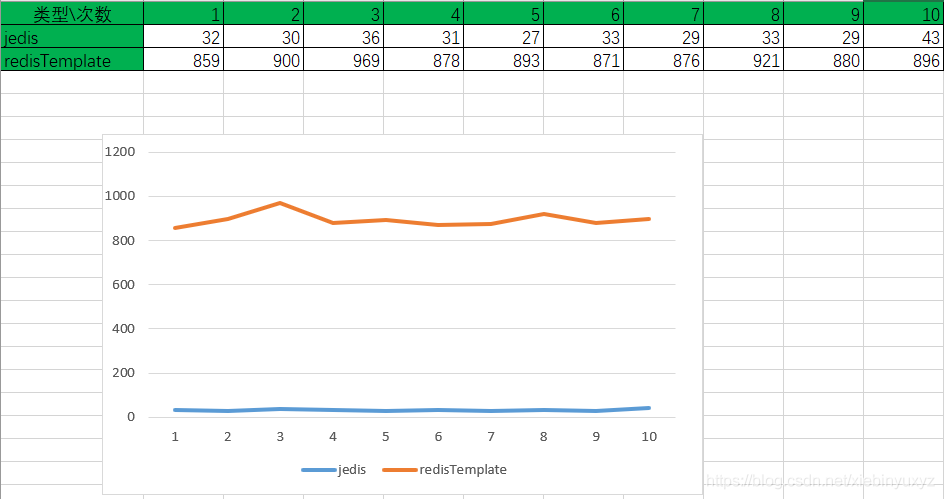
就是从redis读取对应的key的值,使用100次耗费的时长,单位毫秒
第一版
属于只读缓存方案,1.就是删改直接删缓存,2.增加直接加入数据库。3.查时到缓存取,没有再从数据库中加载,再放到缓存
回复:数据库那块不属于缓存工具类的职责,不用写


