怎么判断那些对象应该回收
引用计数算法
在对象中添加一个引用计数器,每当一个地方引用它时,计数器就加一;当引用失效时,计数器值就减一;任何时刻计数器为零的对象就是不可能再被使用的。
问题:不能解决循环依赖,对象1和对象2相互引用的话不会被回收,比如下面代码:
public class ReferenceCountingGC {
public Object instance;
public ReferenceCountingGC(String name) {
}
public static void testGC(){
ReferenceCountingGC a = new ReferenceCountingGC("objA");
ReferenceCountingGC b = new ReferenceCountingGC("objB");
a.instance = b;
b.instance = a;
a = null;
b = null;
}
}可达性分析算法
根对象作为起始节点集合,从根节点开始,根据引用关系向下搜索,搜索过程所走过的路径称为引用链,如果某个对象到GC Roots间没有任何引用链相连就可以被回收。
GCRoots的对象包括下面几种:
- 虚拟机栈(栈帧中的局部变量区,也叫做局部变量表)中引用的对象。
- 方法区中的类静态属性引用的对象。
- 方法区中常量引用的对象。
- 本地方法栈中JNI(Native方法)引用的对象。
被判定不可达对象,不是一定会被回收:经过第一次标记后的对象,根据 此对象是否有必要执行finalize()方法 进行筛选,随后会由收集器对
F-Queue中的对象进行第二次小规模的标记
三色标记
- 白色:表示对象尚未被垃圾回收器访问过。若在分析结束的阶段,仍然是白色的对象,即代表不可达。
- 黑色:表示对象已经被垃圾回收器访问过,且这个对象的所有引用都已经扫描过。黑色的对象代表已经扫描过,它是安全存活的,如果有其它的对象引用指向了黑色对象,无须重新扫描一遍。黑色对象不可能直接(不经过灰色对象)指向某个白色对象。
- 灰色:表示对象已经被垃圾回收器访问过,但这个对象至少存在一个引用还没有被扫描过。
为什么会产生浮动垃圾
- 一种是把原本消亡的对象错误的标记为存活,这不是好事,但是其实是可以容忍的,只不过产生了一点逃过本次回收的浮动垃圾而已,下次清理就可以。
- 一种是把原本存活的对象错误的标记为已消亡,这就是非常严重的后果了,一个程序还需要使用的对象被回收了,那程序肯定会因此发生错误。
原来应该是黑色的对象被误标为了白色的两个必要条件:
条件一:赋值器插入了一条或者多条从黑色对象到白色对象的新引用。
条件二:赋值器删除了全部从灰色对象到该白色对象的直接或间接引用。
于是产生了两种解决方案:增量更新(Incremental Update)和原始快照(Snapshot At The Beginning,SATB)。
在HotSpot虚拟机中,CMS是基于增量更新来做并发标记的,G1则采用的是原始快照的方式。
增量更新
增量更新要破坏的是第一个条件(赋值器插入了一条或者多条从黑色对象到白色对象的新引用),当黑色对象插入新的指向白色对象的引用关系时,就将这个新插入的引用记录下来,等并发扫描结束之后,再将这些记录过的引用关系中的黑色对象为根,重新扫描一次。
可以简化的理解为:黑色对象一旦插入了指向白色对象的引用之后,它就变回了灰色对象。
原始快照(SATB)
原始快照(Snapshot At the Begining)要破坏的是第二个条件(赋值器删除了全部从灰色对象到该白色对象的直接或间接引用),当灰色对象要删除指向白色对象的引用关系时,就将这个要删除的引用记录下来,在并发扫描结束之后,再将这些记录过的引用关系中的灰色对象为根,重新扫描一次。
这个可以简化理解为:无论引用关系删除与否,都会按照刚刚开始扫描那一刻的对象图快照开进行搜索。
增量更新用的是写后屏障(Post-Write Barrier),记录了所有新增的引用关系。
原始快照用的是写前屏障(Pre-Write Barrier),将所有即将被删除的引用关系的旧引用记录下来。
垃圾回收算法
标记-清除算法MarkSweep
先把内存区域中的这些对象进行标记,哪些属于可回收标记出来,然后把这些垃圾拎出来清理掉。会产生内存碎片。
复制算法Copying
它将可用内存按容量划分为大小相等的两块,每次只使用其中的一块。当这一块的内存用完了,就将还存活着的对象复制到另外一块上面,然后再把已使用过的内存空间一次清理掉。
标记-整理算法MarkCompact
与标记-清除算法一样,但后续步骤不是直接对可回收对象进行清理,而是让所有存活的对象都向一端移动,再清理掉端边界以外的内存区域。
分代收集算法
在新生代中,每次垃圾收集时都发现有大批对象死去,只有少量存活,那就选用复制算法,只需要付出少量存活对象的复制成本就可以完成收集。
在老年代中,因为对象存活率高、没有额外空间对它进行分配担保,就必须使用标记-清理算法或者标记-整理算法来进行回收。
垃圾收集器
Serial/Serial Old
单线程收集器,并且在它进行垃圾收集时,必须暂停所有用户线程。Serial收集器是针对新生代的收集器,采用的是Copying算法,Serial Old收集器是针对老年代的收集器,采用的是Mark-Compact算法。它的优点是实现简单高效,但是缺点是会给用户带来停顿。
ParNew
ParNew收集器是Serial收集器的多线程版本,使用多个线程进行垃圾收集。
Parallel Scavenge
新生代的多线程收集器(并行收集器),它在回收期间不需要暂停其他用户线程,其采用的是Copying算法,该收集器与前两个收集器有所不同,它主要是为了达到一个可控的吞吐量。
Parallel Old
Parallel Scavenge收集器的老年代版本(并行收集器),使用多线程和Mark-Compact算法。
CMS
Concurrent Mark Sweep:将STW打散, 让一部分GC线程和用户线程并发执行。
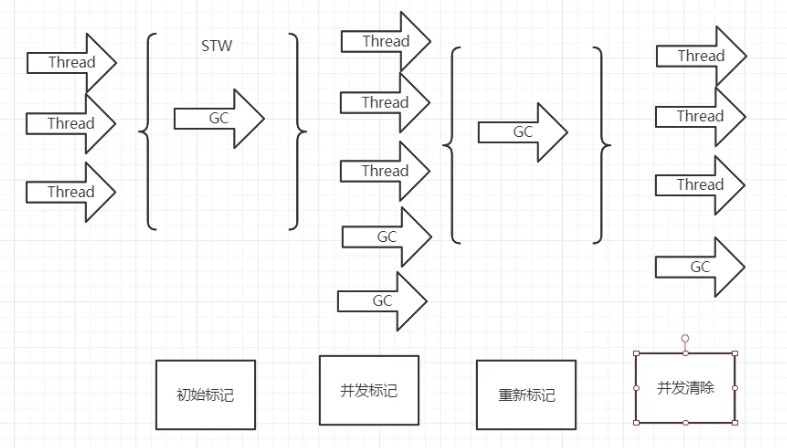
- 初始标记:STW,只标记出GC Roots直接引用的对象。
- 并发标记:继续标记其他对象,并发执行。
- 重新标记:STW,对并发执行阶段的对象进行重新标记。
- 并发清除:并发将产生的垃圾清除。
安全点,即程序执行时并非在所有地方都能停顿下来开始GC,只有在到达安全点时才能暂停。
G1 Garbage First 垃圾优先
对堆内存不在分old和eden,而是划分为一个一个小内存块Region。每个Region可以隶属于不同的年代。
G1不会产生内存碎片
新生代和老年代不再是物理隔离。Region的大小是一致的,数值是在1M到32M字节之间的一个2的幂值数,JVM会尽量划分2048个左右、同等大小的Region。
G1收集器之所以能建立可预测的停顿时间模型,是因为它可以有计划地避免在整个Java堆中进行全区域的垃圾收集。
过程
- 初始标记:STW,标记出GC Roots直接引用的Region。
- 标记Region:通过RSet标记出初始标记的Region引用的Old区Region。
- 并发标记:跟CMS差不多,只需遍历第二步标记出的Region。
- 最终标记:STW,跟CMS差不多。
- 筛选回收:跟CMS不同,G1可以采用拷贝算法。这个阶段G1只选择垃圾较多的Region清理。
使用了Remembered Set来避免全堆扫描,G1中每个Region都有一个与之对应的RememberedSet ,在各个 Region 上记录自家的对象被外面对象引用的情况。当进行内存回收时,在GC根节点的枚举范围中加入RememberedSet 即可保证不对全堆扫描也不会有遗漏。
卡表
在进行Minor GC的时候,我们可以不用扫描整个老年代,而是在卡表中寻找脏卡,并将脏卡中的对象加入到Minor GC的GC Roots里。当完成所有脏卡的扫描之后,Java虚拟机便会将所有脏卡的标识位清零。
想要保证每个可能有指向新生代对象引用的卡都被标记为脏卡,那么Java虚拟机需要截获每个引用型实例变量的写操作,并作出对应的写标识位操作。
卡表能用于减少老年代的全堆空间扫描,这能很大的提升GC效率。
CMS和G1的对比
| CMS | G1 | |
|---|---|---|
| JDK版本 | 1.6以上 | 1.7以上 |
| 回收算法 | 标记——清除 | 标记——整理 |
| 运行环境 | 针对70G以内的堆内存 | 可针好几百G的大内存 |
| 回收区域 | 老年代 | 新生代和老年代 |
| 内存布局 | 传统连续的新生代和老年代区域 | Region(将新生代和老年代切分成Region,默认一个Region 1 M,默认2048块) |
| 浮动垃圾 | 是 | 否 |
| 内存碎片 | 是 | 否 |
| 全堆扫描 | 是 | 否 |
| 回收时间可控 | 否 | 是 |
| 对象进入老年代的年龄 | 6 | 15 |
| 空间动态调整 | 否 | 是(新生代5%-60%动态调整,一般不需求指定) |
| 调优参数 | 多(近百个) | 少(十几个) |


